[Python] Summarizing and Translating Foreign Tech Articles Using Generative AI

Table of Contents
I implemented a feature to summarize DevTo articles in Japanese and send them to Discord (repository: https://github.com/rmc8/DevToDigest).
Overview
In the previous article, “[Python] Fetching Article Information from Dev Community (dev.to) via API” (/introduction_devtopy), I created a module to handle DevTo’s API using Python. Additionally, with the advent of GPT-4o-mini, individuals can now access high-performance models at a low cost via API, expanding the possibilities based on ideas (meanwhile, Gemini 1.5 Flash models under 128K are available at half the price of 4o-mini!). As it’s said that there’s no silver bullet in programming, having various techniques and flexible ideas is a key weapon. Reading articles from overseas, which have a different culture from Japan, can help Japanese programmers develop unique perspectives. For me, even reading Japanese articles feels tedious, so I wrote this program to summarize English articles into Japanese, making it easier to read interesting ones.
Code
The code is mainly divided into three parts: (1) Article retrieval, (2) Article processing using Langchain and generative AI, (3) Data sending to Discord.
Article Retrieval
Articles are retrieved using devtopy.
def fil_articles(
articles: PublishedArticleList, threshold: int
) -> List[PublishedArticle]:
return [a for a in articles.articles if a.positive_reactions_count > threshold]
res = dt.articles.get(page=1, per_page=1000, tag=tag_name.lower())
articles = fil_articles(res, reaction_threshold)This fetches up to 1000 articles being read that day and passes the data and threshold to the fil_articles function. The threshold is a filter based on the number of positive reactions, with a default value of 55, which roughly corresponds to the top 2% of reactions. This ensures we’re dealing with sufficiently popular articles. By focusing on popular ones, we can reduce LLM costs and concentrate on high-quality content, providing an incentive to read even for those weak in English (English learning * high-quality tech articles).
Afterward, since the retrieved and filtered article list doesn’t include the full content, we fetch the article details. We use DevTo’s API for this but check SQLite to see if it’s been processed by LLM before, to minimize requests. This SQLite is local, so it determines based on what the individual has read.
for article in articles:
url = str(article.url)
if db.url_exists(url):
continue
article_id = article.id
detail: Union[ErrorResponse, Article] = dt.articles.get_by_id(article_id)
if type(detail) is ErrorResponse:
continue
title = article.title
tags = article.tag_list
contents = detail.body_markdownIf the URL has already been processed, it skips; otherwise, it requests detailed information using the article ID. If successful, it retrieves the title, tags, and article content, then proceeds to translation and summarization with LLM.
Article Processing with Langchain and Generative AI
Preparation for processing is done in the LangProcGpt class. This class handles requests to generative AI and returns structured data.
class LangProcGpt:
MODEL_NAME = "gpt-4o-mini"
def __init__(
self,
title: str,
contents: str,
url: str,
img_url: str,
tag_list: List[str],
api_key: str,
):
self.title = title
self.contents = contents
self.url = url
self.tag_list = tag_list
self.img_url = img_url
self.llm = ChatOpenAI(
model_name=self.MODEL_NAME, temperature=0, api_key=api_key
)
parser = PydanticOutputParser(pydantic_object=ProcResult)
self.result_parser = OutputFixingParser.from_llm(
parser=parser,
llm=self.llm,
)The actual LLM processing is done on the title and contents, while the rest is for returning structured data or authenticating the OpenAI API. Processing is executed via the run method.
# main.py
params = {
"title": title,
"contents": contents,
"url": url,
"img_url": detail.social_image,
"tag_list": tags,
"api_key": os.getenv("OPENAI_API_KEY"),
}
lp = LangProcGpt(**params)
data = lp.run(summary_sentences=summary_sentences)def run(self, summary_sentences: int = 5) -> ProcessedArticleData:
result = self.summarize_and_translate(summary_sentences)
res_dict = {
"en_title": self.title,
"ja_title": result.ja_title,
"url": self.url,
"img_url": str(self.img_url),
"tags": ", ".join([f"#{t}" for t in self.tag_list]),
"ja_summary": result.ja_summary,
}
return ProcessedArticleData(**res_dict)In run, the processing is consolidated in summarize_and_translate, and the final result is compiled into res_dict for structured data return. Let’s check the prompts and processing step by step.
Summarizing
def summarize_and_translate(self, summary_sentences: int):
summary = self.summarize(summary_sentences) # Here
ja_summary = self.translate(summary)
ja_title = self.translate(self.title)
# (Omitted)Summarization is done in the summarize method, with an argument indicating the number of sentences for the summary. Since English text tends to be longer than Japanese for the same meaning, summarizing into N sentences rather than N characters is more appropriate for meaningful breaks.
def summarize(self, summary_sentences: int):
prompt = PromptTemplate(
template=SUMMARIZE_PROMPT_TEMPLATE,
input_variables=["summary_sentences", "contents"],
)
formatted_prompt = prompt.format(
summary_sentences=summary_sentences, contents=self.contents
)
output = self.llm.invoke(formatted_prompt)
return output.contentThe summarize method uses a template to create the prompt.
SUMMARIZE_PROMPT_TEMPLATE = """
## Instructions
Please summarize the following English text into a narrative of {summary_sentences} sentences in plain text format.
## Text
================================================================
{contents}
================================================================
""".strip()The prompt instructs to summarize the English text into a narrative of N sentences in plain text format. This prevents simple bullet points and ensures a contextual, narrative summary. The text is passed in a block delimited by === to avoid conflicts with Markdown code blocks.
Translating the Summary to Japanese
Next, the summarized text is passed to a translation task. While GPT-4o-mini is cost-effective and high-performance, breaking tasks down simply improves accuracy. So, we first summarize in English and then translate the summary. The prompt is as follows:
JA_TRANSLATE_PROMPT_TEMPLATE = """
## Instructions
Please translate the following text into Japanese.
## Text
{text}
""".strip()This is a simple prompt to translate the given text into Japanese. Since the previous summarization step outputs plain text, it’s directly input here. The article title is also translated using the same prompt.
Structuring the Data
After completing the summary and its translation, as well as the title translation, we structure the data.
class ProcResult(BaseModel):
ja_title: str = Field(description="Japanese translation of the article title")
ja_summary: str = Field(description="Japanese translation of the summary")
def summarize_and_translate(self, summary_sentences: int):
summary = self.summarize(summary_sentences)
ja_summary = self.translate(summary)
ja_title = self.translate(self.title)
formatted_instructions = self.result_parser.get_format_instructions()
prompt = PromptTemplate(
template=PARSE_PROMPT_TEMPLATE,
input_variables=["ja_title", "ja_summary"],
partial_variables={"formatted_instructions": formatted_instructions},
)
formatted_prompts = prompt.format(ja_title=ja_title, ja_summary=ja_summary)
output = self.llm.invoke(formatted_prompts)
return self.result_parser.parse(output.content)formatted_instructions defines the structure of the desired data. It specifies returning a structured object with the Japanese title and summary, including descriptions for clarity. This automates making the LLM understand the structure via Langchain. After creating the prompt, we format it and invoke the LLM, then parse the output into structured data.
PARSE_PROMPT_TEMPLATE = """
## Instructions
Please return an object containing a Japanese title and a Japanese summary.
## Input
### Japanese Title
{ja_title}
### Japanese Summary
{ja_summary}
## Output Format
{formatted_instructions}
""".strip()The prompt instructs to return a structured object with the Japanese title and summary. It passes the translated title and summary as input and the structure definition for output.
prompt = PromptTemplate(
template=PARSE_PROMPT_TEMPLATE,
input_variables=["ja_title", "ja_summary"],
partial_variables={"formatted_instructions": formatted_instructions},
) # Create the prompt template
formatted_prompts = prompt.format(ja_title=ja_title, ja_summary=ja_summary) # Format with values
output = self.llm.invoke(formatted_prompts) # Invoke the model
return self.result_parser.parse(output.content) # Parse into structured dataThis completes the process, returning the Japanese title and summary in a structured, programmable format.
Sending the Processed Results to Discord
We use the structured data to send it to Discord. No need to create a bot; we can use the Webhook feature for easy messaging. After sending, if there’s no error, we record it in the database; otherwise, we move to the next article.
lp = LangProcGpt(**params)
data = lp.run(summary_sentences=summary_sentences)
err_status = dw.report(data)
if err_status:
continue
db.insert_data(
url=data.url,
en_title=data.en_title,
ja_title=data.ja_title,
translated_text=data.ja_summary,
tags=data.tags,
)Data sending to Discord doesn’t use a dedicated library but can be done easily with requests.
import requests
from .model import ProcessedArticleData
class DiscordWebhookClient:
def __init__(self, webhook_url: str, is_silent: bool = True):
self.webhook_url = webhook_url
self.is_silent = is_silent
def report(self, proc_data: ProcessedArticleData) -> int:
embed = {
"color": 0x00C0CE,
"title": proc_data.ja_title,
"url": proc_data.url,
"fields": [
{"name": "EnTitle", "value": proc_data.en_title},
{"name": "Tags", "value": proc_data.tags},
{"name": "Summary", "value": proc_data.ja_summary},
],
"image": {"url": proc_data.img_url},
}
data = {
"content": "",
"embeds": [embed],
}
if self.is_silent:
data["flags"] = 4096
headers = {"Content-Type": "application/json"}
response = requests.post(self.webhook_url, json=data, headers=headers)
if response.status_code in (200, 204):
return 0
return response.status_codeInstantiate with the Webhook URL and silent notification setting, then pass the structured data to send it formatted.
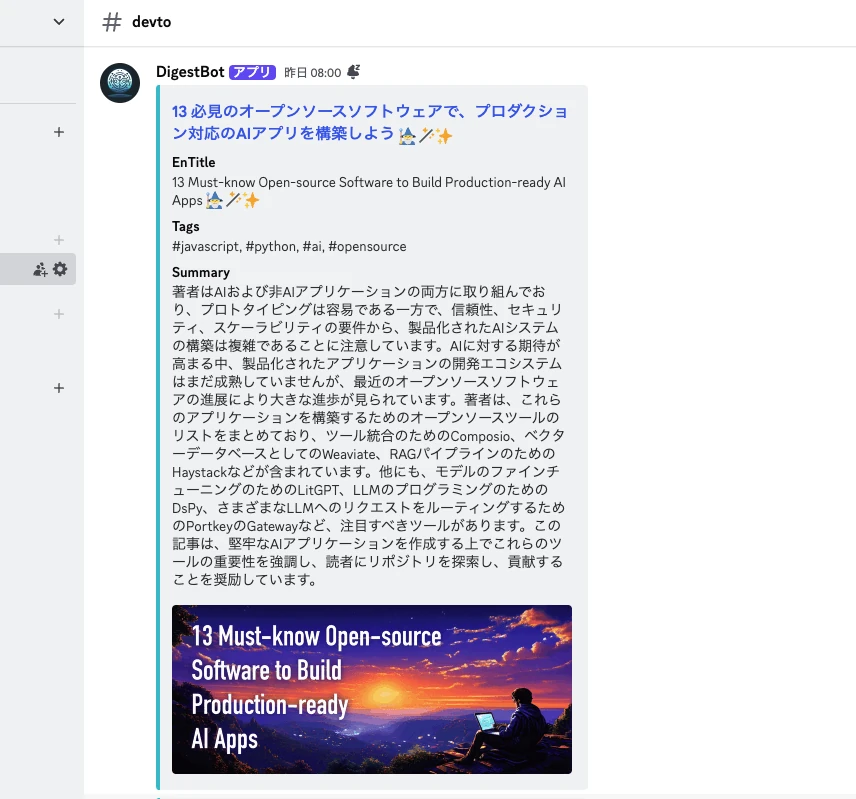
It sends the Japanese title with link, original English title, tags, summary, and article eyecatch, making it visually appealing and easy to decide whether to read the article in Japanese.
Usage
You can send articles to Discord by running the command like this:
python main.py {tag name} {Webhook URL} {reaction threshold}I’m using it on a Raspberry Pi 3 with a script like this for automation:
WEBHOOK_URL="https://discord.com/api/webhooks/xxxxxxxxxxx/yyyyyyyyyyyyyyzzzzzzzzzzzzz"
SCRIPT_PATH="$HOME/auto/DevToDigest/src/main.py"
THRESHOLD=100
cd $HOME/auto/DevToDigest/src
python3 $SCRIPT_PATH python $WEBHOOK_URL $THRESHOLD
python3 $SCRIPT_PATH typescript $WEBHOOK_URL $THRESHOLD
python3 $SCRIPT_PATH svelte $WEBHOOK_URL $THRESHOLD
python3 $SCRIPT_PATH flutter $WEBHOOK_URL $THRESHOLD
python3 $SCRIPT_PATH dart $WEBHOOK_URL $THRESHOLD
python3 $SCRIPT_PATH llm $WEBHOOK_URL $THRESHOLDThis aggregates and sends information related to Python, web, Flutter, or LLM, as I’m interested in them.
Thoughts
I’ve been using this since August 7th, and it’s helped me develop a habit of reading overseas tech articles, bookmarking interesting ones. There are best practices summarized in Japan, but also information not seen there, and the quality of popular articles is high. I charged only 5 dollars and after 10 days, it’s used just 0.07 dollars, so it’s very cost-effective. It’s great for simple tasks, and with ideas, GPT-4o-mini can handle more complex ones too.
Summary
Recent small-scale generative AI models are low-cost and high-performance, offering individuals the potential to realize ideas that were previously difficult. Although not mentioned here, Function calling for task routing is also affordable now. By identifying what generative AI can do, composing prompts and overall processing, and executing ideas, you can create surprising apps. I hope this article serves as a simple starting point for such processing.
Related Books
Note: These are Amazon affiliate links.
- ChatGPT/LangChainによるチャットシステム構築[実践]入門: From the Engineer Selection series, it’s reliable in quality. However, Langchain has evolved quickly, so the book’s content is outdated; check GitHub for updates. It’s useful for learning system construction, prompts, and processing if you’re okay with checking the latest info on GitHub.
- LangChain完全入門 生成AIアプリケーション開発がはかどる大規模言語モデルの操り方: More focused on basics than the above, it intensively covers prompt engineering and Langchain fundamentals. Note that the code might be hard to read due to line breaks in the book version, and content is aging.
- 大規模言語モデルを使いこなすためのプロンプトエンジニアリングの教科書: This covers prompt engineering and ideas before using Langchain, serving as a prompt and idea collection. It’s helpful for thinking about Langchain applications and general AI handling.











Loading comments...