【Python】생성AI를 이용하여 해외 기술 기사를 요약하고 번역하기

Table of Contents
DevTo의 기사를 일본어로 요약하여 Discord에 전송하는 기능을 추가했습니다(리포지토리: https://github.com/rmc8/DevToDigest).
개요
【Python】Dev community (dev.to)에서 API로 기사 정보를 가져오기에서는 Python으로 DevTo의 API를 조작하기 위한 모듈을 만들었습니다. 또한, GPT 4o-mini의 등장으로 개인도 우수한 성능의 모델을 저렴한 가격으로 API를 통해 사용할 수 있게 되면서 아이디어에 따라 활용 범위가 확대되고 있습니다(지난 기사 사이에 Gemini1.5 Flash의 128K 이하 모델이 4o-mini의 절반 가격으로 사용할 수 있게 되었습니다!). 그리고 프로그래밍에서는 은의 총알이 없다고 말하듯이 다양한 기법과 유연한 사고를 가지는 것이 하나의 무기가 되며, 일본과는 다른 문화가 있는 해외 기사를 읽는 것도 일본에서 독특한 사고를 가진 프로그래머가 되는 데 도움이 될 것입니다. 저에게는 일본어 기사조차 귀찮게 느껴지기 때문에, 영어 기사를 일본어로 요약하여 쉽게 관심 있는 기사를 읽을 수 있도록 이 프로그램을 작성했습니다.
코드
코드는 주로 세 부분으로 구성되어 있습니다. (1) 기사의 획득, (2) Langchain을 사용한 생성AI에서의 기사 처리, (3) Discord로 데이터 전송입니다.
기사의 획득
기사는 devtopy를 사용하여 획득합니다.
def fil_articles(
articles: PublishedArticleList, threshold: int
) -> List[PublishedArticle]:
return [a for a in articles.articles if a.positive_reactions_count > threshold]
res = dt.articles.get(page=1, per_page=1000, tag=tag_name.lower())
articles = fil_articles(res, reaction_threshold)그날 읽고 있는 기사를 1000건 획득하여 fil_article 함수에 데이터와 임계값을 전달합니다. 이 임계값은 긍정적인 반응이 얼마나 있는지를 필터링하는 데 사용되며, 기본값으로 55가 설정되어 있습니다. 55의 긍정적인 반응은 대략 상위 2%의 반응 수입니다. 따라서 충분히 인기 있는 기사라고 판단할 수 있습니다. 인기 있는 기사에 집중하여 LLM의 비용을 줄이거나 고품질 기사에 집중할 수 있으므로, 영어가 약해도 읽을 수 있는 인센티브가 됩니다(영어 학습 * 고품질 기술 기사).
그 후, 획득하고 필터링한 기사 목록에는 기사의 콘텐츠가 포함되어 있지 않으므로 기사를 획득합니다. 기사의 획득에는 DevTO의 API를 사용하지만 요청 수를 줄이기 위해 과거에 LLM으로 처리한 적이 있는지 SQLite로 확인합니다. 이 SQLite는 로컬에 생성되므로, 개인이 읽은 것인지 여부를 판단하는 메커니즘입니다.
for article in articles:
url = str(article.url)
if db.url_exists(url):
continue
article_id = article.id
detail: Union[ErrorResponse, Article] = dt.articles.get_by_id(article_id)
if type(detail) is ErrorResponse:
continue
title = article.title
tags = article.tag_list
contents = detail.body_markdown처리된 URL이 존재하는 경우 처리를 건너뛰고, 처음 처리하는 기사의 경우 그 기사의 ID를 사용하여 상세 정보를 API에 요청합니다. 기사의 획득에 성공하면, 제목, 태그, 기사 정보를 획득하여 LLM에 의한 번역과 요약 처리로 이동합니다.
Langchain을 사용한 생성AI에서의 기사 처리
LangProcGpt 클래스로 처리 준비를 합니다. 이 클래스에서는 생성AI에 대한 처리 요청과 구조화된 데이터를 반환하는 역할을 합니다.
class LangProcGpt:
MODEL_NAME = "gpt-4o-mini"
def __init__(
self,
title: str,
contents: str,
url: str,
img_url: str,
tag_list: List[str],
api_key: str,
):
self.title = title
self.contents = contents
self.url = url
self.tag_list = tag_list
self.img_url = img_url
self.llm = ChatOpenAI(
model_name=self.MODEL_NAME, temperature=0, api_key=api_key
)
parser = PydanticOutputParser(pydantic_object=ProcResult)
self.result_parser = OutputFixingParser.from_llm(
parser=parser,
llm=self.llm,
)실제로 LLM으로 처리하는 것은 title과 contents이며, 나머지는 단순히 구조화된 데이터를 반환하거나 OpenAI API의 인증에 키를 사용하는 것입니다. 처리는 run 메서드를 실행하여 수행할 수 있습니다.
# main.py
params = {
"title": title,
"contents": contents,
"url": url,
"img_url": detail.social_image,
"tag_list": tags,
"api_key": os.getenv("OPENAI_API_KEY"),
}
lp = LangProcGpt(**params)
data = lp.run(summary_sentences=summary_sentences)def run(self, summary_sentences: int = 5) -> ProcessedArticleData:
result = self.summarize_and_translate(summary_sentences)
res_dict = {
"en_title": self.title,
"ja_title": result.ja_title,
"url": self.url,
"img_url": str(self.img_url),
"tags": ", ".join([f"#{t}" for t in self.tag_list]),
"ja_summary": result.ja_summary,
}
return ProcessedArticleData(**res_dict)run을 보면 처리가 summarize_and_translate에 집중되어 있으며, 최종 결과를 res_dict에 모아서 구조화된 데이터를 반환합니다. 하나씩 프롬프트나 처리 내용을 확인합니다.
요약하기
def summarize_and_translate(self, summary_sentences: int):
summary = self.summarize(summary_sentences) # 여기
ja_summary = self.translate(summary)
ja_title = self.translate(self.title)
# (생략)요약은 summarize 메서드로 수행합니다. 인수에는 요약할 문장 수를 나타내는 정수를 전달합니다. 영어로 N자 요약하면 같은 의미의 문장도 영어가 길어지기 쉽습니다. 의미 있는 구분으로 문장을 나누면 N자 요약보다 N문 요약이 적절하다고 판단했습니다.
def summarize(self, summary_sentences: int):
prompt = PromptTemplate(
template=SUMMARIZE_PROMPT_TEMPLATE,
input_variables=["summary_sentences", "contents"],
)
formatted_prompt = prompt.format(
summary_sentences=summary_sentences, contents=self.contents
)
output = self.llm.invoke(formatted_prompt)
return output.contentsummarize 메서드에서는 템플릿 기능을 사용하여 프롬프트를 만드는 처리를 합니다.
SUMMARIZE_PROMPT_TEMPLATE = """
## Instructions
Please summarize the following English text into a narrative of {summary_sentences} sentences in plain text format.
## Text
================================================================
{contents}
================================================================
""".strip()프롬프트 내용으로는 영어 텍스트를 {summary_sentences} 문장으로 나레이티브 형식으로 요약하여 평문 형식으로 출력하도록 지시합니다. 이는 목록 등으로 쉽게 요약하는 것을 방지하고, 문맥을 포착한 상태에서 문장 형식으로 요약시키기 위해 이와 같은 프롬프트를 작성했습니다. 요약할 텍스트는 Text 블록에 ===로 구분하여 전달합니다. 코드 블록으로 구분하면 Markdown의 코드 블록과 충돌할 수 있으므로, ===로 텍스트를 전달하고 있음을 나타냅니다.
요약을 일본어로 번역하기
그 후, 요약한 문장을 다시 번역하는 작업에 전달합니다. GPT 4o-mini는 저가격 고성능이지만 더 정확하게 작업을 수행하기 위해 단순히 작업을 분해하는 것이 좋습니다. 따라서 영어로 먼저 요약하는 작업을 요청한 후, 요약한 것을 번역하는 순서로 체인을 구성하여 의도한 내용을 얻을 수 있도록 합니다. 프롬프트 내용은 다음과 같습니다.
JA_TRANSLATE_PROMPT_TEMPLATE = """
## Instructions
Please translate the following text into Japanese.
## Text
{text}
""".strip()단순히 전달된 텍스트의 언어를 일본어로 바꾸도록 작성한 프롬프트입니다. 이전 요약 처리에서 평문 텍스트를 반환하도록 지시했기 때문에, 텍스트에 블록에는 그대로 텍스트를 입력하고 있습니다. 또한, 기사의 제목도 같은 프롬프트로 사용하며, 간단히 번역할 수 있습니다.
데이터를 구조화하기
여기까지의 처리로 요약 → 요약의 번역, 기사 제목의 번역이 완료되었습니다. 완료된 데이터를 구조화하는 처리를 수행합니다.
class ProcResult(BaseModel):
ja_title: str = Field(description="Japanese translation of the article title")
ja_summary: str = Field(description="Japanese translation of the summary")
def summarize_and_translate(self, summary_sentences: int):
summary = self.summarize(summary_sentences)
ja_summary = self.translate(summary)
ja_title = self.translate(self.title)
formatted_instructions = self.result_parser.get_format_instructions()
prompt = PromptTemplate(
template=PARSE_PROMPT_TEMPLATE,
input_variables=["ja_title", "ja_summary"],
partial_variables={"formatted_instructions": formatted_instructions},
)
formatted_prompts = prompt.format(ja_title=ja_title, ja_summary=ja_summary)
output = self.llm.invoke(formatted_prompts)
return self.result_parser.parse(output.content)formatted_instructions는 반환할 데이터의 구조를 정의하고 있습니다. 일본어 제목과 일본어 요약을 구조화된 데이터로 반환하도록 하며, ja_title, ja_summary의 설명을 기술하고 있습니다. 설명을 포함한 형식으로 정의하여 langchain을 사용하여 LLM이 이해하기 쉬운 형태로 설명을 자동화하고 있습니다. 설명을 만든 후, 요약이나 번역과 마찬가지로 프롬프트의 템플릿에 값을 삽입합니다.
PARSE_PROMPT_TEMPLATE = """
## Instructions
Please return an object containing a Japanese title and a Japanese summary.
## Input
### Japanese Title
{ja_title}
### Japanese Summary
{ja_summary}
## Output Format
{formatted_instructions}
""".strip()프롬프트 내용으로는 구조화된 객체로 일본어 제목과 번역한 요약을 반환하도록 지시하고 있습니다. 구조화된 데이터를 만들기 위한 입력에 기사의 제목과 번역한 요약을 전달하고, 출력 처리에는 langchain으로 만든 구조화된 데이터의 정의를 전달합니다. 템플릿에서 프롬프트를 만든 후 GPT 4o-mini에 프롬프트를 전달하고, 그 결과에서 JSON 형식으로 데이터를 추출하는 처리를 합니다.
prompt = PromptTemplate(
template=PARSE_PROMPT_TEMPLATE,
input_variables=["ja_title", "ja_summary"],
partial_variables={"formatted_instructions": formatted_instructions},
) # 프롬프트의 템플릿을 만듦
formatted_prompts = prompt.format(ja_title=ja_title, ja_summary=ja_summary) # 값을 삽입한 프롬프트를 획득
output = self.llm.invoke(formatted_prompts) # 모델에 프롬프트를 전달하여 응답을 얻음
return self.result_parser.parse(output.content) # 응답에서 형식 정의에 맞춰 구조화된 상태의 데이터를 추출이 처리를 통해 일본어 제목과 일본어 요약을 구조화된(프로그램에서 다룰 수 있는) 상태로 전달할 수 있습니다.
Discord에 처리 결과를 전송하기
구조화된 데이터를 사용하여 Discord에 데이터를 보냅니다. Bot 등을 만들 필요 없이 Webhook 기능을 사용하면 쉽게 메시지를 보낼 수 있습니다. 데이터 전송 방법은 이 후에 설명하지만, 전송 후 에러가 발생하지 않으면 데이터베이스에 처리된 기록을 하고, 그렇지 않으면 다음 기사의 처리를 수행합니다.
lp = LangProcGpt(**params)
data = lp.run(summary_sentences=summary_sentences)
err_status = dw.report(data)
if err_status:
continue
db.insert_data(
url=data.url,
en_title=data.en_title,
ja_title=data.ja_title,
translated_text=data.ja_summary,
tags=data.tags,
)Discord로 데이터 전송은 전용 라이브러리를 사용하지 않았지만, requests를 사용하면 쉽게 할 수 있습니다.
import requests
from .model import ProcessedArticleData
class DiscordWebhookClient:
def __init__(self, webhook_url: str, is_silent: bool = True):
self.webhook_url = webhook_url
self.is_silent = is_silent
def report(self, proc_data: ProcessedArticleData) -> int:
embed = {
"color": 0x00C0CE,
"title": proc_data.ja_title,
"url": proc_data.url,
"fields": [
{"name": "EnTitle", "value": proc_data.en_title},
{"name": "Tags", "value": proc_data.tags},
{"name": "Summary", "value": proc_data.ja_summary},
],
"image": {"url": proc_data.img_url},
}
data = {
"content": "",
"embeds": [embed],
}
if self.is_silent:
data["flags"] = 4096
headers = {"Content-Type": "application/json"}
response = requests.post(self.webhook_url, json=data, headers=headers)
if response.status_code in (200, 204):
return 0
return response.status_code인스턴스화 시 Webhook의 URL과 무음 알림 설정의 유무를 전달하고, 실제로 Discord로 데이터를 전송할 때 구조화된 데이터를 전달하기만 하면 정형화된 상태로 데이터를 전송할 수 있습니다.
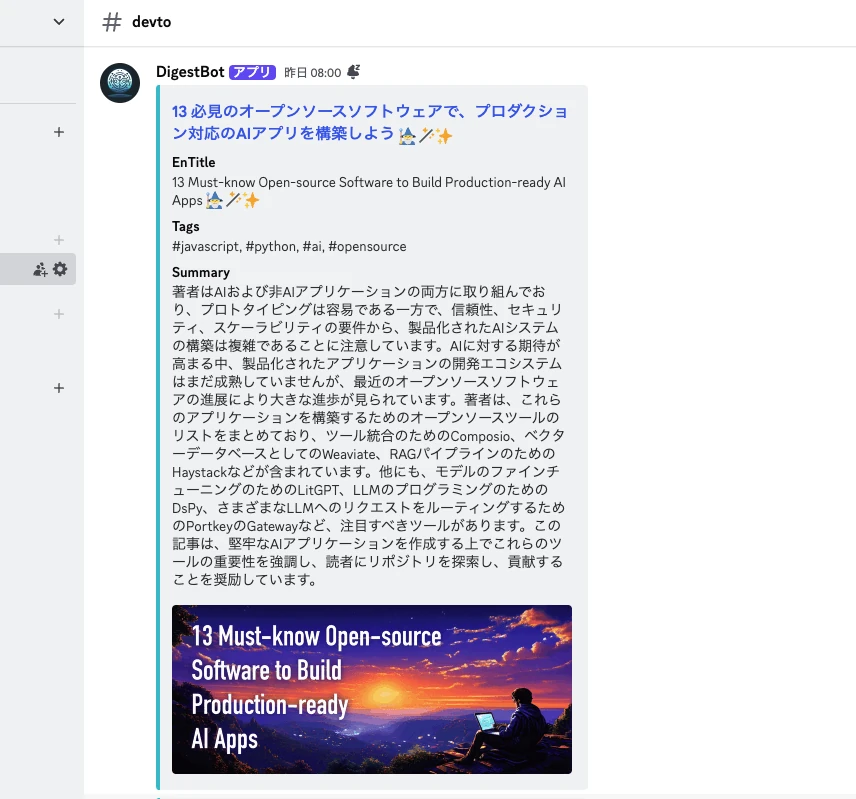
링크가 포함된 일본어 제목, 영어 원본 제목, 태그, 요약, 기사의 아이캐치를 전송할 수 있으므로 시각적으로도 기사에 대한 관심을 유발하고, 일본어로 이 기사를 읽을지 말지 빠르게 판단할 수 있습니다.
사용법
아래와 같이 명령어를 입력하면 Discord로 기사를 전송할 수 있습니다.
python main.py {태그 이름} {Webhook의 URL} {반응의 임계값}저는 Raspberry Pi3에서 다음과 같은 스크립트를 자동 실행시키고 있습니다.
WEBHOOK_URL="https://discord.com/api/webhooks/xxxxxxxxxxx/yyyyyyyyyyyyyyzzzzzzzzzzzzz"
SCRIPT_PATH="$HOME/auto/DevToDigest/src/main.py"
THRESHOLD=100
cd $HOME/auto/DevToDigest/src
python3 $SCRIPT_PATH python $WEBHOOK_URL $THRESHOLD
python3 $SCRIPT_PATH typescript $WEBHOOK_URL $THRESHOLD
python3 $SCRIPT_PATH svelte $WEBHOOK_URL $THRESHOLD
python3 $SCRIPT_PATH flutter $WEBHOOK_URL $THRESHOLD
python3 $SCRIPT_PATH dart $WEBHOOK_URL $THRESHOLD
python3 $SCRIPT_PATH llm $WEBHOOK_URL $THRESHOLDPython, web, Flutter, LLM에 관심이 있으므로 그 관련 정보를 모아서 전송하도록 하고 있습니다.
감상
8월 7일부터 사용하고 있지만 해외 기술 기사를 읽고 관심 있는 기사를 북마크하여 읽는 습관이 생겼습니다. 일본에서도 요약된 베스트 프랙티스도 있지만, 일본에서는 보지 못하는 정보도 있으며 인기 기사의 품질은 높습니다. 5달러만 충전하여 10일 동안 사용하고 있지만 아직 0.07달러만 사용된 상태로, 이 정도면 매우 저렴하다고 생각합니다. 단순한 작업에도 좋고, 아이디어가 있으면 더 복잡한 작업에도 GPT 4o-mini는 유용할 것입니다.
요약
요즘 생성AI의 소규모 모델은 저가격 고성능으로, 개인이라도 지금까지는 어려웠던 아이디어를 실현할 가능성을 가지고 있습니다. 여기서는 언급하지 않았지만 처리 내용에 따라 실행할 처리를 분배하는 Function calling도 저렴하게 다룰 수 있게 되었으므로, 생성AI로 할 수 있는 것을 파악하고, 프롬프트나 전체 처리를 구성하여 그 아이디어를 실행하면 놀라운 앱도 만들 수 있을 것입니다. 먼저, 간단한 처리의 발판으로서 이 기사가 도움이 되었으면 합니다.
관련 도서
※이것은 Amazon으로의 링크입니다.
- ChatGPT/LangChain에 의한 채팅 시스템 구축 [실천] 입문: 엔지니어 선서 시리즈로 품질에 오류가 없습니다. 다만, langchain의 발전이 빠르고 책 자체의 내용이 오래되어 GitHub에서 최신 내용이 업데이트되고 있습니다. 처리의 조합이나 프롬프트의 구성 등 시스템 구축의 참고가 되므로, GitHub에서 최신 정보를 보는 것이 어렵지 않다면 추천합니다.
- LangChain 완전 입문 생성AI 애플리케이션 개발이 촉진되는 대규모 언어 모델의 다루기:↑의 책보다 기초에 중점을 둔 책으로 프로ンプ트 엔지니어링이나 Langchain의 기초를 집중적으로 배울 수 있습니다. 다만, 코드가 줄 바꿈되어 표시되어 책 버전은 보기 불편했고, 마찬가지로 내용이 오래되어 주의가 필요합니다.
- 대규모 언어 모델을 활용하기 위한 프로ンプ트 엔지니어링의 교과서:Langchain을 사용하는 것보다 더 이전 단계에서 프로ンプ트 엔지니어링이나 아이디어에 접할 수 있는 책입니다. 이것은 프로ンプ트나 아이디어 모음 같은 느낌이므로 Langchain에서 어떻게 적용할지 고려하는 계기가 되며, 일상적인 생성AI의 다루기에도 유용하므로 추천합니다.










댓글을 불러오는 중...